Algorithm for Multi-frame Super-Resolution Processing
In multi-frame super-resolution, information is reconstructed from multiple images of the same subject.
Suppose two (frames) low-resolution images are shifted by 0.125 pixels to the right and 0.1875 pixels downwards. In a 4x higher-resolution image, the images are shifted by 0.5 pixels to the right and 0.75 pixels downwards.
The average luminance value of a 4x4 square corresponding to one pixel of the first frame's image is equal. By performing sub-pixel alignment on the 4x resolution image, the corresponding part of the second frame that corresponds to the same pixel is obtained as the square indicated by the bold line on the right side of the diagram. It is assumed that the average luminance value of that part is equal to one pixel of the corresponding low-resolution image.
By using this information, the luminance values of each pixel in the high-resolution image are corrected. By repeating this correction, information that is not present in the low-resolution image can be restored on the high-resolution image.
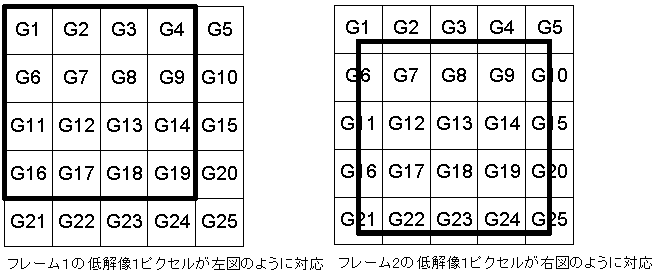
As can be understood from this explanation, multi-frame super-resolution is based on the technique of aligning two images.
At our company, we are developing a multi-frame super-resolution program using the sub-pixel alignment technique that we used to construct a defect inspection system for product labels and inspection target images.
As can be seen from the algorithm, multi-frame super-resolution has the following constraints:
- The object must be stationary
- Multiple slightly shifted images are required
Due to constraint (1), it is not possible to reconstruct a high-resolution video from a low-resolution video without modification. There are few video contents where the object is stationary.
We are currently researching and developing super-resolution processing methods that can be applied even when the object is in motion.
Applications include converting analog broadcasts to high-definition and high-definition to 4K2K vision.
Creating high-definition and 4K2K content incurs significant costs, but if software-based resolution enhancement of low-resolution video assets can be achieved, it would greatly reduce the cost of creating high-resolution content.
Reference: As of 2007, renting a 4K2K-compatible camera costs 400,000 yen/day.
From constraint (2), it can be observed that in cases where the camera is fixed on a tripod, for example, the multi-frame super-resolution process cannot be used if there is no shift between multiple images.
In situations like recording videos on a mobile phone, having some degree of camera shake is actually convenient. In activities such as astronomical observation, the captured object image shifts due to the Earth's rotation, so even with a fixed camera, it is possible to obtain a super-resolution image.
There are also studies that use systems where multiple cameras simultaneously capture images, similar to stereo cameras.
|






