Three Methods to Improve the Accuracy of Large-Scale Language Model (ChatGPT) Responses
The structure of this article is as follows:- Why Large-Scale Language Models (ChatGPT) Make Errors in Search/Inference/Computation
- Understanding how large-scale language models work can help understand why ChatGPT inferences (including search) are bound to make errors.
- Three methods to improve the accuracy of large-scale language models (ChatGPT)
- Improving Accuracy through Large-Scale Expansion (Difficult for Users to Participate)
- The Main Method to Achieve 60% to 90% Accuracy: Prompt Engineering (Fine-Tuning)
- ChatGPT + GPT-4 vs. Bing
- Sample Project for Fine-Tuning
- Limitations of Prompt Engineering (Fine-Tuning)
- Method to Achieve 90% or Above Accuracy: Combination with Existing Programs
Why does large-scale language model (ChatGPT) search and inference make mistakes?
Even with simple knowledge queries, ChatGPT makes mistakes. One clear reason is that the text ChatGPT is trained on is outdated, dating back more than a year. Until it was able to integrate with web search (Microsoft's Bing), it couldn't even answer questions about today's weather.However, even with queries about facts that ChatGPT should have learned prior to 2021, frequent errors occur. If you use it expecting it to be similar to Google search, you will encounter many confusions due to the numerous inaccuracies it provides. For example, when asked about the "2018年の本屋大賞(2018 Bookstore Award)" that ChatGPT should have learned about, it displays a ranking that is completely different from the actual list (as of late June 2023).
2018年の本屋大賞のランキングを教えてください。 【2018年の本屋大賞ランキング】 1位:「おしりのこ」(ななし太郎著) 2位:「波よ聞いてくれ」(イトウヒロミ 著) 3位:「氷酒村」(今井秀樹 著) 以下略 ----------------------------------------- 本来のランキングは以下の通り 大賞 かがみの孤城 辻村深月 2位 盤上の向日葵 柚月裕子 3位 屍人荘の殺人 今村昌弘 以下略The first place "おしりのこ(Oshirinoko)" and the third place "氷酒村(Hyoshumura)" are both of unknown origin, including the author's name. The second place "波よ聞いてくれ(Nami yo Kiite Kure)" ranked fourth in the 2020 "Manga Taisho".
Since the top 10 rankings are completely random, we decided to ask ChatGPT again using a larger-scale GPT-4 model.
2018年の本屋大賞のランキングを教えてください。 私の知識が2021年までのものであるため、2018年の本屋大賞のランキングを提供できます。 以下に該当の情報を記載します: 1位: 「かがみの孤城」 (辻村深月) 2位: 「コンビニ人間」 (村田沙耶香) 3位: 「九月が永遠に続けば」 (恩田陸) 以下略1st place is the correct answer. 2nd place is the 9th work in 2017. 3rd place is the winner of the 2004 Horror Suspense Award, but the author is not "恩田陸(Riku Onda)" but "沼田まほかる(Mahokaru Numata)". Why does ChatGPT make mistakes? You can understand the reason if you infer how ChatGPT is learning.
Understanding how large language models work makes it clear that ChatGPT will inevitably make mistakes in inference (including searches).
Using ChatGPT as a search engine often leads to incorrect results. This is because ChatGPT does not search the internet for information when asked questions.What does ChatGPT do?
ChatGPT performs a "complement" or "fill in the blank" process, assuming that there are blanks in the text. Essentially, it is similar to a "fill in the blanks" language exercise.
Complete the sentence with an appropriate word. 〇〇〇〇〇に当てはまる言葉を入れなさい。 吾輩は猫である。名前はまだない。どこで生れたか頓と見当がつかぬ。 何でも薄暗いじめじめした所で〇〇〇〇〇泣いていた事だけは記憶している。 正解は「ニャーニャー」 (I am a cat. I don't have a name yet. I have no idea where I was born. All I remember is crying "___________" in a dark and damp place place. The correct answer is "meow meow".)
| Candidate | Probability |
|---|---|
| meow meow | 0.25 |
| mya mya | 0.25 |
| sobbing | 0.05 |
| forever | 0.02 |
The user's "inquiry" is a fill-in-the-blank question where the "blank" is located at the end of the text.
ChatGPT does not search the internet based on user inquiries and does not actually perform calculations for input arithmetic problems.
ChatGPT's training is conducted as follows:
- Prepare a large amount of (non-blank) text. In the case of ChatGPT, based on the comparison with other large-scale language models, it is estimated that it has been trained on approximately 1000GB of text data.
- Conduct inference with ChatGPT using randomly placed blanks and random parameters. The size of the blanks can vary, ranging from a few tokens (token ≒ word) to 100 tokens, and they can be concentrated in one place or scattered in multiple places.
- Adjust the parameters, which are estimated to be around 350 billion (estimated based on the number of parameters and performance of GPT-3, which is 175 billion, and PaLM, which is 540 billion), as numerical values between 0 and 1.0 to minimize the difference between the generated text and the original text. By repeating this process with a large amount of text, the accuracy of the fill-in-the-blank questions improves.
- Repeat the training until a sufficient accuracy is achieved. Even for fill-in-the-blank questions with inputs other than the trained text, a sufficient accuracy can be obtained (known as generalization).
The Japanese Wikipedia, a huge online encyclopedia, is known to every Japanese person. The Japanese version of Wikipedia contains less than 4GB of text data as of the first quarter of 2023.
In ChatGPT, it has been trained on more than 250 times the amount of text data compared to Japanese Wikipedia.
By the way, the text data of Japanese Wikipedia is estimated to be several times the total amount of Japanese text that an average Japanese person would hear and read in their lifetime.
(Estimated based on the average reading time, average viewing time of media, and survey data on the number of words spoken in a day by researchers at the University of Maryland)
The initial results only reflect the frequency of word occurrence and generate context-free text.
| ChatGPT is the evolution of the GPT model,(which stands for Generative Pre-trained Transformer.) |
| complementation of 1 token |
|---|
| ChatGPT is the ○○ of the GPT model, |
 To train a model, leave "evolution" blank and learn to predict blank tokens from non-"evolution" tokens. |
| ChatGPT is the evolution of the ○○ model, |
| complementation of 2 tokens |
| ChatGPT is ○○ of the ○○ model, |
| ChatGPT ○○ the ○○ of the GPT model, |
| complementation of more than 3 tokens |
| ChatGPT is evolution of the GPT model, which ○○ for ○○ ○○ Transformer. |
| ChatGPT is the ○○ of the ○○ ○○, which stands ○○ ○○ ○○ ○○. |
- Explain briefly what parameters are used for learning.
- Tokenize the text. Tokens are similar to words. For example, the present participle form "running" would be a separate token, so it is not strictly equal to a word.
- Represent each token with a vector of several hundred to several thousand dimensions and learn the values of these vectors. If we assume a simple 3-dimensional vector, "man" and "woman" would be represented as follows:
- It has been observed that the accuracy of the fill-in-the-blank task improves significantly after learning beyond the total number of parameters surpassing 10 billion. GPT-3 learns with billions of parameters. ChatGPT uses around 350 billion parameters (estimated), and GPT-4 learns with 500 billion to several trillion parameters (estimated, although there are reports of 100 trillion, which are incorrect). Google's latest large-scale language model also surpasses 1 trillion parameters.
- Learn thousands of billions of parameters using a massive amount of text. GPT-3 learns with 1,000 gigabytes of text. Japanese Wikipedia text is less than 4 gigabytes (expected by 2023). This implies learning trillions of parameters using 250 times more text than Japanese Wikipedia.
man = [0.56, 0.01, 0.23] woman = [0.06, 0.61, 0.20]If we consider only 2 words that have been learned, the number of parameters is very small (probably less than 100). This includes the weights of the input token vector, deep learning networks, networks, and the connection weights between networks and output tokens.
Three methods to improve the accuracy of the large-scale language model (ChatGPT) (scaling up/prompt engineering/integration with existing programs)
The three methods are (1) scaling up the language model, (2) prompt engineering (fine-tuning), and (3) integration with existing programs.There are also several other proposed methods that are not discussed in this article, either because actual systems have not been developed as of July 2023, or because they have been developed but have not been evaluated or have not achieved the expected level of accuracy.
For example, there have been developments in creating language models focused on specific fields such as medical papers and law and precedents to improve accuracy. Limited models are also available for use in ChatGPT.
- Accuracy improvement through scaling up (selecting the largest model among the choices presented to users) Increasing the size (parameters) of the language model improves the accuracy of all tasks of the language model.
- Prompt engineering (fine-tuning) is the key to achieving 60% to 90% accuracy Let's reconsider the "fill-in-the-blank" problems that the large-scale language model uses for training.
- How to achieve an accuracy of 90% or more = Intercepting the inference and calculation part The details are explained in the link above, but it is a combination system that adds a linguistic interface using a large-scale language model to existing software.
Re-training parameters for scaling up requires enormous computing power and electricity. User-level involvement in this process is rare, and it is mainly done by the providers of the language model (large companies, universities, research institutes).
What users can do is select a larger model from the options provided.
"Mother scolded Hanako, saying, "______!"With only the above information, there are various possibilities such as "Do it quickly," "Be quiet," "Clean up," and it cannot be narrowed down.
"Hanako didn't finish eating even after 30 minutes. Mother scolded Hanako, saying, "______!" "Hanako is making noise while talking on the phone. Mother scolded Hanako, saying, "______!" "It's mealtime, but Hanako left her toys out. Mother scolded Hanako, saying, "______!"Prompt engineering means adding context and clues, and ChatGPT can solve fill-in-the-blank problems more accurately by using the information of the context.
In addition, the accuracy of the answer improves when important information is described towards the end of the prompt.
Inputting "important information" at the beginning and end of the input sentence of the language generation AI leads to better results, according to Stanford University, among others.
In order to prevent ChatGPT from generating unconvincing answers, it is recommended to give instructions such as "Answering in formal language" and "Answering in a well-formatted way".
Various "tips" tailored to the application can be researched and released in papers and on the internet, such as GPT detection software wrongfully judged most of non-native English essays generated by AI.
There is a more effective method related to prompt engineering. This method, called "Fine-tuning by prompting experts" was proposed in the "Chain of thought" paper (see here).
Fine-tuning involves preparing pairs of data, consisting of prompts and the ideal response text that should be generated, in the range of tens to hundreds of thousands (the actual number depends on the difficulty of the problem). Only a small portion of layers in the large-scale language models are retrained.
By keeping the majority of the parameters in the large-scale language models fixed and only retraining a subset, fine-tuning is a technique that improves the accuracy of neural networks with low computational cost.
In the research of "Chain of thought" paper, it has been found that the accuracy of answers can be significantly improved by supplementing the thought process leading to the answer instead of generating the answer directly in response to user input (question or request).
It requires a great deal of effort for users to supplement the thought process, but over time, large-scale language models learn how to supplement the thought process.
For about 10,000 problems, by supplementing the thought process until the answer, the accuracy of arithmetic word problems, which was below 10% with the 175 billion parameter model of the large-scale language model GPT-3, has improved to the 30% range, and the accuracy, which was in the 30% range with the 540 billion parameter model of the large-scale language model PaLM, has improved to the 50% range.
Since it is based on existing software, it can be considered as a limited-purpose chatbot.
This includes issuing invoices and estimates involving money, creating financial statements, and educational software that serves as a substitute for private tutors. In the medical and legal fields, Currently, expert checks are essential, but in the future, tasks that can be entrusted to AI alone may also emerge. For example, let's consider a mathematical processing system.
As of May 2023, when inquired with ChatGPT (equivalent to GPT-3.5), it generates absurd answers when it becomes slightly more complicated as follows.
Prompt: What is the value of X in the equation 22-(4*5-3*X)=20? ChatGPT: Simplifying the equation, we have 22-20+15X=20, which becomes 2+15X=20. Solving for X, we get 15X=18, and X=1.2. Therefore, X is 1.2. Prompt: What is the value of X in the equation 22-(4*5-3*X)=20? ChatGPT: Simplifying the equation, we have 22-20+X=20, which becomes X=-2. Therefore, X is -2.In order to do that, we assume the use of existing mathematical software. Mathematical software is a software that solves equations (systems of equations), converts units, and sometimes solves word problems.
The analysis of the problem statement is done by ChatGPT, which outputs a formatted text that suits the input of the mathematical software, such as a system of equations. In this case, it involves the mathematical part.
It may involve removing "How many?" and replacing "×" with "*". The equations are processed by the mathematical software, and the output "X=6" and the process of expanding the equation are generated as a prompt for ChatGPT to present to the user.
1. Increasing Accuracy through Scaling (Difficult for Users)
To develop a language model with higher accuracy than ChatGPT, a grid computer consisting of hundreds to thousands of GPUs is required.Currently, it is not possible to train a larger language model than ChatGPT on a local computer.
|
However, there are many large-scale language models that are smaller in scale than ChatGPT. Among them, it is possible to obtain one that can be executed on a local PC, which is comparable to "Llama 2" that rivals ChatGPT (3.5) Running "Llama 2" on a local PC as a Competitor to ChatGPT (3.5). Unfortunately, it seems that the accuracy is lower than that of ChatGPT. By limiting the training to specific types of text, it is possible to achieve accuracy similar to or even surpassing ChatGPT in the specific field that was trained. This effect has been observed. However, the accuracy of responses in fields that were not trained is very low. There are attempts to improve accuracy by limiting tokens to Japanese. Based on the results of papers on cross-lingual transfer learning of large-scale language models (training in German and then transferring to French) and mixed-language learning (learning with a mix of German and French tokens), it seems that multilingual learning using tokens from multiple languages is superior to learning with a single language, especially in similar languages. For languages such as Japanese, Chinese, and Korean that are different from European and American languages, as of 2019, caution is necessary when it comes to simultaneous multilingual learning. In the author's experience, to improve the accuracy of deep learning, it is much more effective to provide more training data than to adjust various parameters, algorithms, and the scale and configuration of neural networks. In the long run, it seems that the accuracy of models trained only in Japanese will not be able to catch up with the accuracy of models trained with Japanese + English, Chinese, European languages, and languages from the Asian region combined. |
|---|
To create larger language models, organizations need to invest in high-performance GPUs, such as those costing around 5 million yen each, with a total of 256 GPUs (including servers and facilities) amounting to an infrastructure cost of around 3 billion yen. Additionally, they would need to budget over 10 million yen per month for electricity costs.
Using the NVIDIA® NVLink® Switch System, it is possible to connect up to 256 H100 units and accelerate exascale workloads. Furthermore, by using a dedicated Transformer Engine, it is possible to implement language models with parameters in the trillions.
ChatGPT offers a paid option to support a model called GPT-4, which has approximately 500 billion to several trillion parameters (estimated based on similar large-scale language models, although not officially disclosed). However, the accuracy of GPT-4 is clearly higher than that of ChatGPT when addressing the same inquiries.
In the case of using GPT-3, a language model with approximately 175 billion parameters, which is about half the parameter count of ChatGPT, to solve a US law examination, the performance ranked in the bottom 10%. However, with GPT-4, a larger-scale language model with approximately 500 billion to several trillion parameters, it achieved a top 10% performance, as discussed in the article"Is the latest and highest-performance large-scale language model GPT-4 really 'AI research'?".
Looking at the score progression of successive natural language processing models in the article"Score Transition of Historical Natural Language Processing Models",
it is evident that large-scale language models prior to the emergence of ChatGPT gradually approach and even surpass human scores in some cases.
Microsoft's Bing and Google's Bard are also moving towards increasing the number of parameters, with Google's cutting-edge prototype model surpassing 1.5 trillion parameters.
Without using prompt engineering or fine-tuning, when solving arithmetic word problems (single-variable arithmetic operations), GPT-3, a model with approximately 175 billion parameters, achieves an accuracy below 10%. However, with a model called PaLM, which has approximately 540 billion parameters, the accuracy increases to 30%. By combining prompt engineering, it is possible to further increase the accuracy by 20-30%, reaching the 30% range for GPT-3 (175 billion parameters) + prompt engineering, and the 50% range for PaLM (540 billion parameters) + prompt engineering.
ChatGPT is GPT-4 Model
By using ChatGPT Plus, the paid plan of ChatGPT, you can utilize GPT-4. As of July 2023, the screen looks as follows. At this point, the number of chats per hour using GPT-4 is limited. The limitations are gradually becoming more relaxed, but they are still quite strict.Normally, chats in ChatGPT are based on GPT-3.5. By selecting GPT-4 with the button on the screen, you can have chats based on GPT-4.

Let's try it with a math word problem.
算数の文章題を解いてください。 ある42人のクラスで国語と算数のテストを行いました。 テストの結果を集計すると算数の合格者は28人で、国語の合格者は25人、 両教科とも合格した者は17人でした。 両教科とも不合格だった者は何人でしょうか? /* GPT-3.5では不正解 */ 両教科とも合格した者は17人であり、算数の合格者は28人、 国語の合格者は25人です。 両教科とも合格している人数よりも算数の合格者数や国語の 合格者数の方が多いことから、 両教科とも不合格だった者の数は次のように計算できます。 算数の合格者数(28人) + 国語の合格者数(25人) - 両教科とも合格した者の数(17人) = 36人 したがって、両教科とも不合格だった者は36人です。 /* GPT-4では正解 */ この問題は集合の問題として解くことができます。 まず、全体の学生数は42人です。 次に、算数の合格者は28人、国語の合格者は25人、 そして両教科ともに合格した学生は17人と与えられています。 しかし、両教科ともに合格した学生の数(17人)は、 算数の合格者の数と国語の合格者の数にそれぞれ含まれています。 したがって、算数と国語の合格者の総数は、28人と25人を足した数 (53人)から17人を引いた数、つまり36人となります。 全体の学生数42人から、算数または国語のどちらか一方でも 合格した学生の数(36人)を引くと、両教科ともに不合格だった 学生の数が求まります。 したがって、両教科ともに不合格だった学生の数は、 42人 - 36人 = 6人となります。
コラム「ぬるぽ」「ガッ!」
10年以上前の話となるが、一部のプログラマクラスタで「ぬるぽ」という問いかけに対して「ガッ」と応えることがはやった。 バグの原因や結果となる"ヌルポインター"が値となる場合にショックを受けるということが由来であるが、特に意味も無く使われることの方が多い。 標準ChatGPTとChatGPT+GPT-4との違いを象徴するような結果なのでコラムとして紹介する。| コラム ぬるぽ がっ |
|---|
|
AIに「ぬるぽ」と送った結果に「吹いた」
ChatGPTに"ぬるぽ"と問いかけると、「ゲッ!」と応えてしまう。 |
3文字以内で返答してください ぬるぽ ゲッ! |
|
ChatGPTの3500億パラメータ(推定値、GPT-3の1750億より多く、PaLMの5400億より少ないとみられている)のモデルでは出力した「ガッ」と「ゲッ!」のベクトル表現に差異が無い(しかも「ゲッ!」の方が高い)ためこのような現象が発生していると思われる。 ところが大規模言語モデルを5000億~数兆パラメータ(PaLM以上という推定値)のGPT-4に切り替えると、 |
3文字以内で返答してください ぬるぽ ガッ |
|
正しく答えが返ってくる。GPT-4になっても、トークンの種類数は大きくは変わらないが、パラメータ数は数倍になっている。 トークンのベクトルの次元やニューラルネットワークの規模が増えため、「ガッ」と「ゲッ!」の出力のベクトル表現に差異が生じて正しい答えが返るようになったと理解できる。 |
Limitations of Scaling Up
While scaling up improves the accuracy of fill-in-the-blank problems, it alone has its limitations.The reasons for this are as follows.
- The scale of the text being used for training is saturated The amount of training text, which is one element of scaling up, does not increase. Currently, training is being done using several TBs of text. The text from the Japanese Wikipedia is approximately 4GB as of 2023, so we are using text that is several hundred times larger than the Japanese Wikipedia. It is conceivable that the amount of text being accumulated on the web will continue to increase, but the following concerns arise.
- Resistance to text scraping In July 2023, Twitter implemented view restrictions as a measure against text scraping. Now that it is known that text data is valuable, there is a possibility of increasing efforts to secure text data.
- Increase in lawsuits related to illegal text data In an article titled "OpenAI sued by authors for unauthorized use of works in ChatGPT training", there was a lawsuit claiming that OpenAI had collected and used illegal text data for training. Similar movements are also observed in image generation AI. With ChatGPT, it is possible to generate summaries and reviews from novel titles. This is also possible for novels that are still under copyright. It indicates that we are using text data from novels whose copyright has not expired.
- Scarcity of high-quality training data The depletion of text data available on the web has also been pointed out. ("Will AI's learning data run out? Impact and countermeasures of the '2026 problem')
- The rapid increase of texts generated by AI in future human societies It has been reported that adding trained text to the training data causes the problem of overfitting. ("What happens when you continue to teach generated AI with 'text created by generated AI'? British team reports it becomes 'useless') This problem is critically serious for AI. When a large-scale language model learns the text generated by another large-scale language model, the flaws are cumulatively amplified. By repeating the training, AI becomes progressively "stupid". The same phenomenon is observed in image generation models. Unless we set a mark that allows humans to distinguish texts created by humans from those created by AI before the contamination of generated AI progresses, it will become hopeless to increase the amount of text used for training AI in the future.
- Increase in computational complexity and power consumption due to parameter growth With the current methods, even with parallel processing, it may take several tens of seconds to obtain a single output. Furthermore, as the number of parameters increases, more GPUs are required for parallelization.
Because of the seriousness of this problem, it has become common practice for developers of generated AI to archive the texts and images created by humans that have not been contaminated by generated AI as an archive.
The texts added for training after 2023 may be limited to a very small number that are clearly recognizable as texts created by humans.
Furthermore, as a strategy for improving the accuracy of large language models, prompt engineering has a greater impact than the benefits of scaling up.
Prompt engineering can also be addressed by the user and is expected to become a significant industry in the future.
2. Prompt Engineering (Fine-tuning) is the key to achieving 60% to 90% accuracy
While scaling requires relying on language model development companies, prompt engineering and fine-tuning can be done by the users themselves. It doesn't require any cost.Although hiring skilled fine-tuning engineers may require high compensation, it is negligible compared to the investment for scaling.
As explained earlier, large language models learn through "fill-in-the-blank questions." They generate text for the blank part based on the contextual text outside the blank space in a probabilistic manner. How does it appear to have a conversation with users in models like ChatGPT?
For large language models like ChatGPT, it is merely a "fill-in-the-blank question" where the input sentence called a prompt in the first half serves as a clue to fill in the blank in the second half.
Naturally, the more information in the contextual non-blank text, the better the accuracy of the fill-in-the-blank. Furthermore, the more specific instructions in the contextual text, the more reasonable the fill-in-the-blank. For example, if there is an instruction such as "within 100 characters," the answer will be concise, and if there is an instruction like "explained in a way that elementary school students can understand," it solves arithmetic word problems without using equations. As of July 2023, specific instructions are sometimes ignored, but this happens only occasionally. It is expected to be resolved eventually.
The accuracy of the answers improves depending on how the prompts are written. It is important to master the technique of writing prompts.
While those who have mastered the technique are sometimes referred to as "prompt engineers," it is not true that they receive high salaries just because they have acquired the technique.
The following are some the key points:
- Make instructions as specific as possible Even if you ask to solve the next arithmetic word problem, sometimes it immediately returns the answer.
- Focus on what should be done rather than what should not be done By saying "Please explain the process to solve the next word problem in 3-5 sentences so that even elementary school students can understand. Equations should be avoided," it explains the process without using equations.
- Important information should be mentioned towards the end of the prompt The proximity of tokens also has a significant impact on accuracy. However, there is also a disadvantage that the later parts are prioritized. When conducting a mock trial with ChatGPT, as the trial has the final argument and statement of the defense at the end, regardless of what the trial is about, the result always ends up as not guilty."No matter what I do, it's always not guilty..." ChatGPT mock trial, plan by a University of Tokyo student faces a crisis As a contrast experiment, when the closing argument and prosecution's request were placed after, everything turned out to be guilty instead. As a solution, mixing the defense and prosecution's statements towards the end or using different methods from the actual trial format seem to be effective, but it doesn't seem to be the decisive factor.
By asking "Please explain the process to solve the next word problem in 3-5 sentences," it explains the process of solving using equations.
Even with "Please explain how to solve the next word problem in 3-5 sentences so that even elementary school students can understand," occasionally it explains the process using equations.
By asking "Please explain how to solve the next word problem in 3-5 sentences without using equations so that even elementary school students can understand," it explains the process without using equations.
During the second AI boom known for projects like the Fifth Generation Computer Systems Project before 1990, there existed Knowledge Engineers who developed rule-based systems (expert systems) that formalized the knowledge of experts. They too were required to possess both rule-based AI knowledge and specialized knowledge. It is safe to say that the prompt engineer is a modern version of Knowledge Engineers.
Being a hybrid of technology and knowledge, they are highly skilled individuals who are naturally employed with exceptional treatment.
In this article, elementary school math word problems are used as the subject matter. While some specialized knowledge is required, such as solving multiple problems without using equations, it is possible for those who have gone on to study STEM fields in university to handle it. Typically, highly specialized knowledge in specialized fields is required.
Let's provide three examples of prompt engineering that require specialized knowledge, starting from simple ones:
- Few shot prompt Several examples of transformations are given, and the prompt is to solve the problem at the end. Knowledge about transformations is necessary. An example of a few shot prompt that converts loanwords written in Katakana to Japanese is as follows:
アダルト|おとな チルドレン|こども カンパニー| アダルト|おとな チルドレン|こども カンパニー|企業Conversion of numerical wordplay is not successful even with dozens of hints provided.
As of June 2023, it seems that few-shot prompts cannot handle numerical wordplay.
Similarly, few-shot prompts cannot handle problems that require extracting numbers that meet certain conditions (including simple conditions such as odd or even) from a series of multiple numbers.
語呂合わせで数字を考えてください。 いちいち|11 はいく|819 よろしく|4649 いいふうふ| いちいち|11 はいく|819 よろしく|4649 いいふうふ|361
Fine-tuning is a method where the parameters of a large-scale language model are used as is, except for the last output layer, and only the parameters of the last output layer are retrained. This method has low computational cost, so it is also available for end-users through the API of ChatGPT.
For example, for the following problem:
つるとかめが合計20匹います。 足の数が合わせて54本のときかめは何匹いますか?Even when trying to find the answer "There are seven turtles" using a GPT-3-based (175 billion parameters) large-scale language model, the accuracy rate is only a few percent. Therefore,
つるとかめが合計20匹います。 足の数が合わせて54本のときかめは何匹いますか? 20匹すべてがかめだとすると、足の数は合わせて80本となります。 かめ1匹がつるになると足の数は合わせて78本となり、2本減ります。 実際の足の数は54本なので、(80-54)/2=13匹がつるとなります。 かめは20-13=7匹となります。 /* 上記の解き方は、方程式を使わない小学生向けの解き方となります。 つるの助数詞は「羽」ですが、問題文に「羽」が出てこないので 「匹」に統一しています */By preparing several dozen examples of the process leading to the solution and fine-tuning, the accuracy rate can be increased several times while maintaining the structure in HTML format. In the original paper, rather than difficult problems like the "crane and turtle" arithmetic puzzles, they focused on arithmetic word problems with one unknown variable using the four fundamental operations.
By preparing 10,000 learning texts and fine-tuning them, the original accuracy rate, which was only one digit, increased to over 30% (over 50% with a large-scale language model called PaLM with 5.4 trillion parameters).
Although it achieves high performance in some tasks, the computational cost for generating texts is very high because multiple calls to generate texts along the "Chain of thought" are required.
It is natural that increasing the computational cost also improves the accuracy.
Furthermore, the complex structure of preparing multiple texts for different thought processes makes the work of prompt engineers, who are experts in each field, more cumbersome. Such criticism exists and will not be discussed further in this paper.
ChatGPT+GPT-4 VS Bing
Here, I would like to analyze the case of solving arithmetic word problems using the commercial ChatGPT based on GPT-4 and Microsoft Bing. As for statistical analysis, it will be conducted in the implementation of fine-tuning.Please note that based on the comparison with a basic large-scale language model without fine-tuning using OpenAI's Playground, it seems that the ChatGPT based on GPT-4 (also applicable to GPT-3.5 base) has clearly been fine-tuned for arithmetic word problems.
Bing also provides similar answers, so it seems to have incorporated fine-tuning or even more elaborate techniques.
Although these are the comparison results as of July 2023, ChatGPT+GPT-4 and Bing have their own strengths and weaknesses, and are almost on par with each other.
For explanations aimed at elementary school students, more than half of the cases with one unknown can be solved successfully.
For cases with two unknowns, it is often beyond the capabilities of human teachers, whether using equations or not, to provide explanations aimed at elementary school students.
Bing is capable of providing explanations approaching the level of human teachers for some of the easier problems.
|
ChatGPT+GPT-4 is correct: Bing is incorrect. Solving without using equations, even without specific instructions. | |
|---|---|
| 長さ200mの列車Aが秒速20mで、長さ150mの列車Bが秒速15mで、同じ方向に進んでいます。 列車Aが列車Bに追いついてから追いこすまで、何秒かかるでしょう。 | |
| GPT-4 |
列車Aが列車Bに追いつき、追い越すためには、 列車Aは列車Bの長さと列車A自身の長さを合わせた距離 を進む必要があります。 それは、200m(列車Aの長さ)と150m(列車Bの長さ)を 合わせた350mです。 しかし、列車Bも前進しているため、列車Aが追いつく速 度は、列車AとBの速度差となります。 それは、20m/秒(列車Aの速度)と15m/秒(列車Bの速度) の差、つまり5m/秒です。 したがって、350mを5m/秒で進む時間は、 350m ÷ 5m/秒 = 70秒です。 従って、列車Aが列車Bを完全に追い越すまでには70秒 かかることになります。 |
| Bing |
列車Aが秒速20mで、長さ200mの列車Aが長さ150mの列車Bに 追いつくまでにかかる時間は、45秒です1 列車Aが列車Bに追いつくまでの距離は、 列車Aの長さ+列車Bの長さです。 列車Aを止めて考えると、列車Bが時速100-20=80km/hで 走行していることになります。 列車Bが追いつくまでにかかる時間は、距離÷速度で求め られます。よって、答えは45秒です 。 |
|
ChatGPT+GPT-4 and Bing are both correct. However, they both fail to provide explanations suitable for elementary school students. ChatGPT+GPT-4 uses force to continue the calculation, while Bing jumps straight to the solution without any explanation. | |
|---|---|
| 現在、しんのすけは5才、みさえは29才です。 みさえの年齢がしんのすけの3倍になるのは何年後でしょう。 | |
| GPT-4 |
しんのすけが5才、みさえが29才の現在から数えて、 みさえの年齢がしんのすけの3倍になるのは何年後か 計算しましょう。 みさえの年齢を3倍した数値がしんのすけの年齢になるとき、 その年数を求めます。 式を立ててみると、以下のようになります: みさえの年齢(29年 + x年) = しんのすけの年齢(5年 + x年) * 3 この等式を解くと、以下のようになります: 29 + x = 3 * (5 + x) 29 + x = 15 + 3x 29 - 15 = 3x - x 14 = 2x x = 7 したがって、みさえの年齢がしんのすけの3倍になるのは7年後となります。 小学生向けに方程式を使わないで説明してください もちろんです。小学生向けにシンプルな方法で説明しますね。 しんのすけが5才で、みさえが29才ですね。みさえの年齢が しんのすけの3倍になるまでには何年かかるか考えてみましょう。 みさえとしんのすけが同じ歳を取るのは1年後ですね。 それから、みさえの年齢がしんのすけの年齢の3倍になるまで、 しんのすけはどれくらい歳を取る必要があるか考えます。 みさえの年齢がしんのすけの3倍になるということは、しんのす けの年齢を3倍した数字がみさえの年齢になるということです。 つまり、しんのすけが6歳になったとき、みさえは18歳(6歳x3) にならなければなりません。 しかし、その時にはみさえはすでに30歳です。それはすでに しんのすけの年齢の5倍です。 次に、しんのすけが7歳になったとき、みさえは21歳(7歳x3) にならなければなりません。 しかし、その時にはみさえはすでに31歳になっています。 これもまた、しんのすけの年齢の4倍以上です。 この計算を続けてみると、しんのすけが12歳になったとき、 みさえは36歳(12歳x3)になるべきです。 その時にはみさえは36歳になっています。 それでは、この条件が満たされるまでに何年かかるかを考えて みましょう。 しんのすけが現在5歳で、12歳になるまでには7年かかります。 したがって、みさえの年齢がしんのすけの3倍になるのは 7年後となります。 |
| Bing |
この問題は、年齢の増加を考えることで解決できます。 しんのすけとみさえの年齢がそれぞれ増加すると、みさえの 年齢はしんのすけの3倍になります。 みさえの年齢がしんのすけの3倍になるまでの時間をx年とすると、 しんのすけの年齢は5+x歳、みさえの年齢は29+x歳です。 みさえの年齢がしんのすけの3倍になることから、 29+x=3(5+x) 29+x=15+3x 2x=14 x=7 したがって、みさえの年齢がしんのすけの3倍になるのは、7年後です。 結論として、みさえの年齢がしんのすけの3倍になるのは7年後です。 小学生向けに方程式を使わないで説明してください もちろんです。方程式を使わずに、次のように考えることができます。 現在、しんのすけは5才、みさえは29才です。 1年後、しんのすけは6才、みさえは30才になります。 2年後、しんのすけは7才、みさえは31才になります。 このように、年々年齢が増加していきます。 みさえの年齢がしんのすけの3倍になるまで 何年かかるかを考えます。 7年後、しんのすけは12才、みさえは36才になります。 このとき、みさえの年齢はしんのすけの3倍になります。 したがって、みさえの年齢がしんのすけの3倍になるのは、 7年後です。 結論として、みさえの年齢がしんのすけの3倍になるのは 7年後です。 |
|
ChatGPT+GPT-4 is incorrect / Bing is correct. ChatGPT+GPT-4 does not use equations, but it is incorrect. Bing, on the other hand, is correct and uses equations. | |
|---|---|
小学生にも分かるように解いてください。 1周30kmの湖の周りを、プリウスは時速60kmで、 フェラーリは時速240kmで、同じ場所から同じ方向に進みました。 フェラーリがプリウスを追い越すのは、出発してから何分後でしょう。 | |
| GPT-4 |
プリウスとフェラーリが1周30kmの湖の周りを走るという 問題ですね。 プリウスが時速60km、フェラーリが時速240kmで進む場合、 フェラーリがプリウスを追い越すのは出発してから何分後か を考えます。 まず、時速60kmで走るということは、1時間に60km走るとい うことです。 同様に、時速240kmで走るということは、1時間に240km走る ということです。そして、1時間は60分です。 それでは、それぞれが1分間にどれくらい走るか計算してみましょう。 プリウスは1時間に60km走るので、 1分には60km ÷ 60分 = 1km走ります。 一方、フェラーリは1時間に240km走るので、 1分には240km ÷ 60分 = 4km走ります。 フェラーリはプリウスよりも早く走るので、 プリウスが1周分(30km)走り終わる前にフェラーリは追い越します。 実際には、フェラーリはプリウスが湖の 半周(30km ÷ 2 = 15km)を走る前に追い越します。 なぜなら、フェラーリがプリウスを追い越すためには、 フェラーリが湖の1周(30km)を走り、その間にプリウスが湖の 半周(15km)を走る必要があるからです。 それでは、フェラーリが湖の1周(30km)を走るのにどれくらいの 時間がかかるかを計算します。 フェラーリは1分に4km走るので、30kmを走るのには 30km ÷ 4km/分 = 7.5分かかります。 したがって、フェラーリがプリウスを追い越すのは出発してから 7.5分後となります。 |
| Bing |
この問題は、速さ、距離、時間の関係を使用して解決できます。 速さは距離を時間で割ったものです。つまり、 距離=速さ×時間です。 プリウスは時速60kmで進みます。つまり、1時間で60km進みます。 1分で60km÷60分=1km進みます。 フェラーリは時速240kmで進みます。つまり、1時間で240km進みます。 1分で240km÷60分=4km進みます。 フェラーリがプリウスを追い越すまでの時間をx分とすると、 フェラーリが進んだ距離は4x km、プリウスが進んだ距離はx kmです。 フェラーリがプリウスを追い越すとき、フェラーリが進んだ距離は プリウスが進んだ距離より30km多くなります。 つまり、4x=x+30 3x=30 x=10 したがって、フェラーリがプリウスを追い越すのは、 出発してから10分後です。 結論として、フェラーリがプリウスを追い越すのは、 出発してから10分後です。 |
以下の例では、ChatGPTが日々改良されていることが見て取れる。実例は挙げていないがBingも段階的に改良されている。
|
ChatGPT+GPT-4:Improved from Incorrect to Correct / Bing Correct For elementary school explanations, ChatGPT+GPT-4 is not good, but Bing is perfect. | |
|---|---|
さいころを1回ふって奇数の目が出ると30点、 偶数の目が出ると10点もらえます。これを20回繰り返すと、 得点は460点になった、奇数の目が出た回数を求めなさい。 | |
| GPT-4(6/30はダメ、7/10は良くなった) 方程式を使わないでとあっても方程式を使う。Bingは正解かつ方程式を使わない説明も完璧 |
/* 2023/06/30では不正解 */ 奇数の目が出たときの点数を30点、 偶数の目が出たときの点数を10点としましょう。 この場合、奇数の目が出た回数をx、偶数の目が出た回数をyとします。 そして全体の試行回数が20回であることから、 次の等式を立てることができます: x + y = 20 (1) また、総得点が460点になったという条件から、 次の等式も立てることができます: 30x + 10y = 460 (2) 等式 (2) から10をくくり出すと: 10(x + y) = 460 よって: x + y = 46 (3) しかし、等式 (1) と (3) が矛盾しています。 20回の試行で460点を得ることは不可能で、 問題文に間違いがあるかもしれません。 再度問題文をご確認いただけますか? /* 2023/07/10では正解! */ さいころの出目が奇数なら30点、偶数なら10点というゲームですね。 20回試行して合計得点が460点になる場合を考えます。 奇数の回数をx、偶数の回数をyとします。 xとyは以下の2つの方程式を満たすはずです。 方程式1: x + y = 20 この方程式はさいころを振った回数が20回であることを 示しています。 方程式2: 30x + 10y = 460 この方程式は得点が合計460点であることを示しています。 方程式2を整理すると、3x + y = 46になります。 これらの方程式を解くために方程式1から方程式2を引くと、 3x + y - (x + y) = 46 - 20 これを整理すると、 2x = 26 x = 26 / 2 よって、x = 13 となります。 したがって、さいころを振って奇数の目が出た回数は13回です。 方程式を使わないで解いてください 略(上記の生成テキストとほぼ同じ) |
| Bing |
この問題は、線形方程式を使用して解決できます。 奇数の目が出た回数をx、偶数の目が出た回数をyとすると、 次のような方程式が得られます。 x + y = 20 (1) 30x + 10y = 460 (2) (1)式から、y = 20 - x (2)式に代入すると、 30x + 10(20 - x) = 460 30x + 200 - 10x = 460 20x = 260 x = 13 したがって、奇数の目が出た回数は13回です。 方程式を使わないで解いてください もちろんです。方程式を使わずに、 次のように考えることができます。 さいころを1回ふって、奇数の目が出ると30点、 偶数の目が出ると10点もらえます。 つまり、奇数の目が出ると偶数の目が出た場合より 20点多くもらえます。 20回繰り返して、得点は460点になりました。 もし、すべての回で偶数の目が出た場合、 得点は20×10=200点になります。 しかし、実際の得点は460点なので、 200点より260点多くなっています。 奇数の目が出ると偶数の目が出た場合より20点多く もらえるので、260÷20=13回、奇数の目が出た と考えられます。 したがって、奇数の目が出た回数は13回です。 方程式を使わないで解いてください(別解) さいころを振って奇数の目が出ると30点、 偶数の目が出ると10点もらえるとのことです。 20回振って合計が460点となる場合、それぞれの さいころの目が出る回数を求めるという問題ですね。 まず、全てのさいころの出目が偶数である場合を考えます。 全て偶数だとすると、10点が20回得られ、合計は200点となります。 しかし、実際の合計得点は460点なので、その差分である 260点分は奇数のさいころの目が出ていた回数によるものです。 奇数のさいころの目が出ると30点、 偶数のさいころの目が出ると10点なので、その差は20点です。 つまり、一回奇数が出るごとに20点ずつ得点が増えると 考えることができます。 そのため、260点は20点ずつ増えた回数と等しいです。 よって、260点 / 20点 = 13回となります。 したがって、奇数のさいころの目が出た回数は13回です。 |
Sample Project for Fine-Tuning
Perform fine-tuning on arithmetic word problems using OpenAI's large-scale language model API.As of July 2023, fine-tuning is not available for the GPT-4 model via the API (only available for use in Chat), so fine-tuning will be done using the GPT-3.5-based model called text-davinci-003.
Fine-tuning is a technique to improve the output accuracy by retraining only a part of the parameters of a neural network that makes up the large-scale language model, using a pair of prompt text specific to a certain domain and the ideal answer text, as previously explained.
In the "Chain of Thought" paper, arithmetic word problems involving the four fundamental operations were fine-tuned using a teaching dataset of 10,000 problems.
For inferring causality from correlation in fine-tuning, fine-tuning was performed using 400,000 problems (researchers investigated whether large-scale language models can estimate "true" causality from correlation (Can Large Language Models Infer "True" Causality from Correlation? Researchers Investigate with 400,000 Problems)).
Since this is a prototype, we will create 100 teaching data for only 1 pattern out of the 30 patterns of word problems and test it.
The project we will build as a sample will focus on word problems related to "passing calculation".
"Passing calculation" refers to problems where vehicles such as trains, cars, and ships pass through a certain point or facility, cross each other, or overtake each other, and it involves calculating speed, distance, and time.
For example, the following is an example problem (original problem).
長さ200mの列車が、時速72kmで走行しています。 この列車が一定の速度でトンネルを通過するとき、 トンネルに入り始めてから完全にトンネルを出るまでに 4分20秒秒かかりました。 トンネルの長さは何mでしょうか?If you prompt the above and ask ChatGPT or Bing, they will calculate the equation without any instructions, so the accuracy is reasonable.
The main purpose of this project is to generate explanations without using equations for elementary school students by adding the prompt "Please explain without using equations, specifically for elementary school students".
However, even with these instructions, the models sometimes continue to use equations, provide explanations that are too complex for elementary school students to understand, or give incorrect answers.
Therefore, the goal of this project is to improve the accuracy of generating explanations for elementary school students by fine-tuning the models. For the example problem mentioned earlier, we will use the following prompt and target text pair:
prompt 方程式を使わないで、小学生にも分かるように解答してください。 長さ200mの列車が、時速72kmで走行しています。 この列車が一定の速度でトンネルを通過するとき、 トンネルに入り始めてから完全にトンネルを出るまでに 4分20秒秒かかりました。 トンネルの長さは何mでしょうか? tunetext [トンネル,入り始め,完全に,出る] [200mの列車,時速72km,4分20秒] [トンネルの長さは何m] 列車の速度は秒速に直すと20m/秒です。 4分20秒で進む距離は20*260=5200mとなります。 進む距離は列車の先頭がトンネルに入ってから列車の末尾が トンネルを出るまでなので、 トンネルの長さ+列車の長さと等しくなります。 したがってトンネルの長さは5000mです。 答え 5000mThe problem starts from "prompt" to "tunetext". The text after "tunetext" is the answer key text.
We will prepare 100 pairs of the above data and convert them into a JSON file. Then, we will pass 90 pairs to the ChatGPT fine-tuning API to generate an improved large-scale language model.
The majority of the instructional data is derived from actual junior high school entrance exam questions, but we cannot publicly release them due to copyright issues. Using the improved large-scale language model, we will compare the scores of the remaining 10 questions (original questions without copyright issues) between a model that did not undergo fine-tuning and a model that did undergo fine-tuning, evaluating the correctness of the answers and explanations.
We will submit the report on October 16, 2023.
Limitations of Prompt Engineering (Fine-tuning)
One significant research question regarding large language models is whether they can infer causal relationships, and a notable study on this topic is discussed in the article " Can large language models estimate the "true" causal relationship from correlation? Researchers investigate with 400,000 problems". Large language models excel at identifying correlation relationships, as they are trained on "fill-in-the-blank" problems. However, it is important to distinguish between correlation and causation. For example, there may be a correlation between tall people and high intelligence, but it does not mean that being tall causes higher intelligence. This is because the high intelligence of taller adults often reflects a different factor than their height, compared to shorter children.In the aforementioned study, fine-tuning was conducted by providing 400,000 texts related to causal relationships, which improved the model's ability to estimate causation to some extent. However, the accuracy rate remained at 30-40%. It became evident that relying solely on textual information, without real-life episodic memories or sensory and emotional experiences, was insufficient (symbol grounding problem).
Furthermore, a fundamental issue with AI generated by large language models is that they probabilistically estimate the text within the context, based on surrounding text. While scaling up improves the accuracy of text estimation and allows for handling larger gaps, it is questionable whether complex inferences can be practically made with reliable accuracy through the purely probabilistic estimation of text within the gap.
3. How to Achieve 90% or More Accuracy = Combination with Existing Programs
When considering only the tasks of "text comprehension" and "text generation," large-scale language models are surpassing human reading comprehension and writing abilities. One method is to combine these "text comprehension" and "text generation" capabilities with "separate programs" such as equation processing systems, expert systems, database searches, and business software. Please note that the "separate program" should be an area-specific technique.An example of an existing famous system is the combination of the equation processing system Wolfram|Alpha and ChatGPT (for more details, refer to "What Is ChatGPT Doing ... and Why Does It Work?" by Stephen Wolfram, the developer of Wolfram|Alpha, published in 2023). ChatGPT converts ambiguous user inputs into the equation processing language "Wolfram|Alpha," and the precise and 100% accurate equation processing system of Wolfram|Alpha processes the equations. ChatGPT then presents the output from Wolfram|Alpha in a user-friendly natural language.
The combination with existing programs is executed using the following steps:
- Convert user input = prompt into input data for the "separate program" using a large-scale language model.
- The "separate program" processes the data and outputs prompts for the large-scale language model.
- The large-scale language model converts the prompts output by the "separate program" into text and presents it to the user.
ChatGPT is considered impressive due to its high reading comprehension and text generation abilities. Even for arithmetic problems that only require the use of the four basic operations, there are problems that require considerable reading comprehension skills.
ChatGPT can solve problems like the following, which are difficult to grasp the meaning of, by cleverly designing the prompts..
高速道路に車が並んでいます。 渋滞の最初の 15 分間に数台の車が通り抜け、 残りの 15 分間にさらに 20 台の車が通り抜けます。 列から 5 台の車が出口を出るので、 渋滞を通り抜ける必要はありません。 高速道路に元々 30 台の車があった場合、 最初の 15 分間に何台の車が渋滞を抜けましたか?The reading comprehension and text generation capabilities of large-scale language models such as ChatGPT are comparable to, or even surpass, those of American university students. According to some surveys, the latest models perform at a level higher than 90% of university students.
However, when it comes to reasoning/fact-checking/planning, even with prompt engineering, the accuracy drops to around 30% for models equivalent to ChatGPT and around 50% for models using GPT-4, even for elementary-level problems.
The aim of this article is to utilize the advanced language abilities of university-level students and handle the infallible aspects of reasoning/fact-checking/planning separately through another program, enabling us to confidently embrace the errors made by ChatGPT.
Utilizing the superior reading comprehension and text generation abilities of large-scale language models
The application and dangers of the dialog-based AI "ChatGPT" that can fluently create misinformation With ChatGPT (GPT-3.5 edition), a correct diagnosis can be made with 50% accuracy by inputting the symptoms of a patient in an emergency room in about 600 words. Although this is too low for actual diagnoses in an emergency room, it is possible to achieve a diagnostic accuracy of over 50% in the future.The reason why AI before ChatGPT couldn't manipulate words like humans "Rinna," the Japanese version chatbot released by Microsoft in 2015, can respond to short question and answer exchanges, but cannot follow along in exchanges with long text and quickly deviates from the context of the conversation. ChatGPT surpasses "Rinna" in all aspects including handling long texts, context, and natural text generation.
What is the successor to ChatGPT, "GPT-4," that passes the American Bar Examination? Exploring its possibilities and risks In a test called "MMLU" designed to measure AI's language inference capabilities, 14,000 multiple-choice questions from 57 categories including natural sciences and humanities were given. In GPT-3.5, the correct answer rate was 70.1%, while in GPT-4, it was 85.5% (for the English test). It is about 5% lower in Japanese.
"90% of Japanese university students can't compete with ChatGPT in terms of writing skills," the concerns of a columnist teaching at a university At the level of mistakenly giving a "良" (good) grade. Grades are ranked from the top as "優" (excellent), "良" (good), "可" (acceptable), "不可" (not acceptable).
Sample Project with Integration of Existing Programs
Replace the text analysis and solution generation parts of the program "Solving Math Word Problems and Providing Solutions for Elementary School Students" previously created using the Prolog language with ChatGPT.The development requires the following three tasks:
- Fine-tuning ChatGPT to convert the input prompt = math word problems into an intermediate representation for the math word problem solver in Prolog.
- Improving the Prolog solver to fit the input/output requirements of ChatGPT.
- Fine-tuning ChatGPT to convert the intermediate representation of the math word problem output to a text presented to the user.
The structure of the Prolog program is simplified as follows:
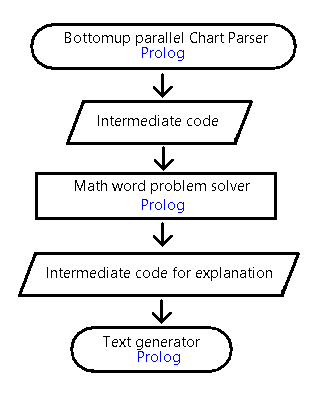
Here is an example of processing using an actual math word problem.
| Process Description and Input/Output Data | Example |
|---|---|
| Math Word Problem | If a total of 8 birds, consisting of cranes and tortoises, have a total of 26 legs, how many birds (how many cranes) are there? Note that cranes have 2 legs and tortoises have 4 legs. |
| Bottom-Up Chart Parser | |
| Input Intermediate Representation | Almost the same as the system combining ChatGPT |
| Math Word Problem Solver using Prolog | |
| Output Intermediate Representation | Almost the same as the system combining ChatGPT |
| Explanation Text and Diagram Generation | |
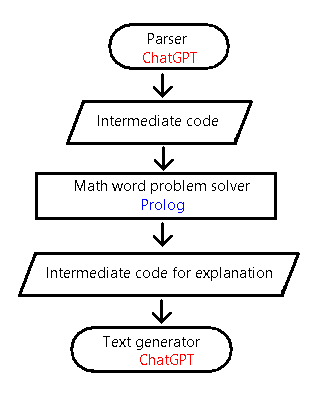
| Process/ Input and Output Data | Example |
|---|---|
| Arithmetic word problem | Tsuru and Kame have a total of 8 animals and a total of 26 legs. How many Tsuru and Kame are there? Tsuru has 2 legs and Kame has 4 legs. |
| ChatGPT (fine-tuned to output intermediate representation) | |
| Input intermediate representation |
top_unit(sum,8,["Tsuru","Kame"],["animals","animals"]). top_attr(sum,26,"number of legs","legs"). howmany(["Tsuru","Kame"]). |
| Prolog-based arithmetic word problem solver | |
| Output intermediate representation |
generate([When replacing all with Tsuru, the number of legs becomes 16.]). generate([When 1 animal becomes Kame, the number of legs increases by 2.]). generate([When 5 animals become Kame, the number of legs increases by 10 and becomes 26.]). generate([The answer is 3 Tsuru and 5 Kame.]). |
| ChatGPT (fine-tuned to generate explanatory text based on input intermediate representation) | |
All the practice problems are actual entrance exam questions for junior high school, so they cannot be publicly shared due to copyright issues. Only the validation problems (10% of the total) are original problems and can be shared publicly.
back