他の深層学習対応OCRとの共通の効果
- 深層学習対応による精度向上 15,000超のフォントパターン、200GB超(グレイスケール)の学習データ。560万パラメータの深層学習による精度向上
(従来型OCRでは600フォントパターン、800MB(モノクロ)のパターンデータを統計的に情報圧縮したもの)
グレイスケール、カラー対応による精度向上
(従来型OCRはモノクロ2値対応。ライブラリ呼び出し前に2値化して利用)
当社の深層学習対応が他と異なるところ
- 高速認識 Core i7-9750H 2.59GHzノートPCで650文字/秒。Core i9-7900X 3.3GHzデスクトップPCで1300文字/秒。
- 認識できないパターンの学習処理は瞬時(1ms以下)に完了。即認識結果に反映。
- 従来型OCRライブラリで登録したユーザーパターン辞書、ユーザー言語辞書といった過去資産を、そのまま利用可能
マルチスレッド処理によりノートPCで3倍~4倍程度の認識速度(2000文字/秒超)が可能。デスクトップPCで10倍程度の認識速度13,000文字/秒が可能。
同時に複数プロセスの認識処理を同時実行可能。ノートPCで4~8プロセス、デスクトップPCで12~16プロセスを、速度低下無しに同時処理。
比較対照:Python+TensorFlow、GPU有りでの認識速度
python+TensorFlow(GPU利用)では350文字/秒(ノートPC条件 Intel Core i7-9750H 2.59GHz NVIDIA Geforce RTX 2060 / 32bit実行)。段落抽出処理、行抽出処理を含む。
| 条件 python+TensorFlow(GPU利用) | 速度 |
|---|---|
| 学習時の推論処理 元から48ピクセル×48ピクセルの文字画像 ミニバッチサイズ1024 | 7000文字/秒 マルチスレッド、マルチプロセス不可 |
| 1文字単位で推論処理を呼び出すケース 元から48ピクセル×48ピクセルの文字画像 ミニバッチサイズ1 | 700文字/秒 マルチスレッド、マルチプロセス不可 |
| 1文字単位で推論処理を呼び出すケース(当社ライブラリとほぼ同一条件(言語処理なし)) 段落抽出/行抽出/文字抽出/48×48ピクセルへの正規化 ミニバッチサイズ1 | 350文字/秒 マルチスレッド、マルチプロセス不可 |
| 1行(平均17文字)単位で推論処理を呼び出すケース(言語処理なし) 段落抽出/行抽出/文字抽出/48×48ピクセルへの正規化 ミニバッチサイズ17 | 1200文字/秒 マルチスレッド、マルチプロセス不可 |
当社の深層学習対応OCRの速度は以下の通り
| 条件 c++版深層学習対応OCRライブラリ | 速度 |
|---|---|
| python+TensorFlow(GPU利用)での学習結果を利用 | |
|
当社ライブラリの動作(1文字単位) 段落抽出/行抽出/文字抽出/48×48ピクセルへの正規化/言語処理あり |
シングルスレッドの深層学習OCRで650文字/秒(ノートPC条件 32bit版)、デスクトップ条件&64bit版では1300文字/秒以上 マルチスレッドで2000文字~10,000文字/秒まで高速化可能 2スレッド利用で1.8倍の高速化が可能、秒速1200文字(ノートPC条件)でpython + TensorFlow(GPU利用)の3倍強の認識速度 4スレッド利用で3.5倍の高速化が可能。秒速2200文字(ノートPC条件)の深層学習利用OCR。python+TensorFlow(GPU利用)の6倍強の認識速度 (4スレッドで4倍の高速化にならないのはCPUキャッシュを利用できないスレッドが生じるためだと思われる) マルチプロセス可能。速度低下無しに4~(ノートPC)、8~(デスクトップPC)プロセスの同時実行 |
対応方針:従来型OCRライブラリとの互換性重視
- ライブラリの既存ユーザーのため32bitでも動作 ライブラリは32bit版と64bit版で提供。32bitアプリケーションを開発している既存ユーザーが多いため、32bitでも動作するように軽量の深層学習モデルを利用した。
- ライブラリの既存ユーザーのためGPUの無い環境での動作/マルチスレッド動作が必要となる 推論部分はC++で記述。GPUは使わずマルチスレッド動作で並列化できるようにするという選択肢を取った。 結果的にシングルスレッドでも、Python/TensorFlow/Keras+GPUよりも高速
- 深層学習を利用することによる精度向上 従来型OCRライブラリが2値画像を対象としていたのに対して、グレイスケール/カラーの文書画像を認識対象とすることで、2値化によるかすれやつぶれの影響を受けなくなる。
- 推論ベースの言語処理(2023年第1四半期にリリース予定) 従来型OCRライブラリでは後続の2文字との連接頻度情報を使った3-gramによる統計的な言語処理を使っていたのに対して前後3文字、合計6文字を使った推論ベースのAI言語処理を利用。
- 従来型OCRライブラリの資産継承 ユーザーが登録したパターンによる優先認識が可能
64bit版ではさらに高速な動作を確認
なお、Python/TensorFlow/Kerasは学習部分では使っている。実質的に学習部分はGPU必須となる。
Python(numpy利用 : GPU利用)版の深層学習OCRも動作確認済みだが、公開はしておらず、性能/機能比較用途にのみ利用している。
| 動作環境 | ||
|---|---|---|
| 従来型OCR | 深層学習OCR | Python版の深層学習OCR |
| 32bit/64bit | 32bit/64bit | 64bit |
| マルチスレッドによる並列動作可能 | マルチスレッドによる並列動作可能 | マルチスレッド動作不可 |
| GPU不要 | GPU不要 | GPU必須(無いと非常に遅い) |
| C++による記述 | C++による記述 | Python/TensorFlow/Kerasによる記述 |
認識対象文字を4000文字から5438文字に増強。1文字あたりのフォントパターンも従来型OCRのモノクロ2値画像300から、グレイスケール画像35,000ファイル超(200GB超)に100倍以上増強。
学習対象のフォント画像のサイズは従来型OCRの150MB程度から200GB程度となっている(文字数増、フォントパターン数増、グレイスケール化による増加)。
データ量の増加に加えて、深層学習を利用することでアルゴリズム自体の精度も向上した。

認識対象文字を1400以上増加、フォントパターンを2桁増、グレイスケール化
3-gram辞書は、300MBの日本語コーパス(30MB程度の日本語コーパス、人名辞書、マイナンバーデータベースを使った全法人辞書、JPのデータベースを使った日本の全住所、広辞苑全見出し語、新潮文庫の100冊全テキスト、日本語wikipedia全見出し語等)から、全ての連続する3文字の組み合わせをカウントして辞書化したものである。
推論ベースのAI辞書は、前後の単語から中央の単語を推測するニューラルネットを、単語では無く日本語の文字に適用して前後の文字から中央の文字を推測するように変更。
従来型OCRのコーパスに3GB超の日本語wikipedia本文を加えた、総計3.7GBのコーパスで学習した推論用の辞書である。
推論ベースの手法の精度は高く、さらにコーパスも10倍以上となっているため、さらに高い精度の言語処理を実現している。
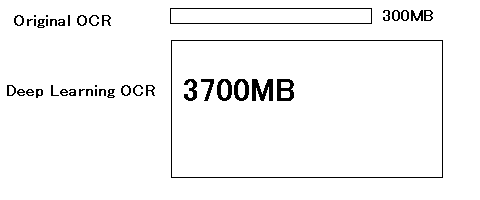
言語辞書の元のコーパスが12倍超。カウントベースからAI推論ベースに。
また、言語処理用の専門用語辞書(旧フォーマット)をそのまま利用可能。図面用語や注記(都道府県市区町村名)、人名等の専門用語辞書を使うことで、さらに精度の高い言語処理が可能。
| 機能・性能比較 | ||||
|---|---|---|---|---|
| 従来型OCR | 深層学習OCR(GPUなし、560万パラメータ) | 深層学習OCR(GPU利用、560万パラメータ) | ||
| 概略 | 2000年リリースの伝統的方式によるOCR C/C++ GPUなし | 従来型OCRの資産を継承しつつ深層学習対応の恩恵も受けることができるモード C/C++ GPUなし |
速度比較専用 python+TensorFlow+Keras GPU利用 | |
| 認識精度 | 高画質99.0%~ 低画質95.0%~ |
高画質99.5%~(誤認識が従来型OCRの1/2) 低画質98%~(低画質で顕著な効果) AI言語処理によりさらに誤認識が減少 精度優先・速度優先の調整が可能 |
高画質99.5%~(誤認識が従来型OCRの1/2) 低画質98%~(低画質で顕著な効果) |
|
| 認識速度(段落抽出、行抽出、文字抽出を含む) | 1300文字~/秒 マルチスレッドで2~10倍以上高速化可能(CPUコア数による) シングルスレッドでpython+TensorFlow GPU利用の4倍弱の速度 |
650文字~/秒 マルチスレッドで2~10倍以上高速化可能(CPUコア数による) 同時多重実行可能 マルチスレッド化したプロセスの同時多重実行も可能 シングルスレッドでもpython+TensorFlow GPU利用の2倍弱の速度 |
350文字/秒 マルチスレッド不可/同時多重実行不可 |
|
| 従来型OCRでユーザー登録したパターン辞書 | 優先して参照 | 優先して参照 | 利用不可 | |
| 言語処理 | 3gram辞書(連接頻度辞書) 専門用語辞書 |
3gram辞書(連接頻度辞書) 専門用語辞書 AI辞書 |
なし | |
| 従来型OCRで登録したユーザー登録言語辞書 | 優先して参照 | 優先して参照 | 利用不可 | |
| 対応画像 | モノクロ2値 グレイスケール/カラーはライブラリ外でモノクロ2値化することで利用 |
モノクロ2値/グレイスケール/カラー | グレイスケールのみ | |